推荐系统入门
推荐系统评测
基于评分准确度
平均绝对误差(MAE)
$$
MAE = \frac {\sum_{(u,i) \in T} |\hat{r}{ui}-r{ui}|} {|T|}
$$
均方根误差(RMSE)
$$
RMSE = \sqrt\frac {\sum_{(u,i) \in T} (\hat{r}{ui}-r{ui})^2} {|T|}
$$
它加大了对预测不准的用户物品评分的惩罚,对系统评测更加严格。
基于预测准确度
一般是对 TopN 推荐的准确度评估,这里的 N 和实际推荐系统场景有关,就是实际每次推荐系统需要输出几个结果。在 TopN 推荐中,设 𝑅(𝑢) 为根据训练建立的模型在测试集上的推荐,𝑇(𝑢) 为测试集上用户的选择。
准确率(Precision)
$$
Precision = \frac {\sum_{u \in U} |R(u) \bigcap T(u)|} {\sum_{u \in U} |R(u)|}
$$
准确率就是:预测正确的/推荐列表的长度,定义为系统的推荐列表中用户喜欢的物品和所有被推荐物品的比率,也称为查准率,即在推荐(预测)的物品中,有多少是用户真正(准确)感兴趣的。
召回率(Recall)
$$
Recall = \frac {\sum_{u \in U} |R(u) \bigcap T(u)|} {\sum_{u \in U} |T(u)|}
$$
召回率就是:预测正确的/用户实际点击列表长度,召回率表示一个用户喜欢的物品被推荐的概率,也称为查全率,即用户喜欢(点击)的物品中,有多少是被推荐了的。
F指标(F-measure)
F-Measure 是 Precision 和 Recall 加权调和平均:
$$
F = \frac {(a^2 + 1)P * R} {a^2(P+R)}
$$
a=1时,就是最常见的F1
基于排序准确度
AUC(Area Under Curve)
被定义为ROC曲线下与坐标轴围成的面积,ROC 全称是 “受试者工作特征”,(receiver operating characteristic)。我们根据学习器的预测结果进行排序,然后按此顺序逐个把样本作为正例进行预测,每次计算出两个重要的值,分别以这两个值作为横纵坐标作图,就得到了 ROC 曲线。ROC 曲线的横轴为 “假正例率”(False Positive Rate,FPR),又称为 “假阳率”;纵轴为 “真正例率”(True Positive Rate,TPR),又称为 “真阳率”。
AUC 这个值在数学上等价于:模型把关心的那一类样本排在其他样本前面的概率。最大是 1,完美结果,而 0.5 就是随机排列,0 就是完美地全部排错。
MAP
’
协同过滤(collaborative filtering)
协同过滤(collaborative filtering)是一种在推荐系统中广泛使用的技术。该技术通过分析用户或者事物之间的相似性,来预测用户可能感兴趣的内容并将此内容推荐给用户。这里的相似性可以是人口特征的相似性,也可以是历史浏览内容的相似性,还可以是个人通过一定机制给与某个事物的回应。比如,A和B是无话不谈的好朋友,并且都喜欢看电影,那么协同过滤会认为A和B的相似度很高,会将A喜欢但是B没有关注的电影推荐给B,反之亦然。
协同过滤推荐分为3种类型:
- 基于用户(user-based)的协同过滤(UserCF算法)
- 基于物品(item-based)的协同过滤(ItemCF算法)
- 基于模型(model-based)的协同过滤 (ModelCF算法)
UserCF算法
UserCF算法的主要步骤如下:
- 找到与目标用户兴趣相似的用户集合
- 找到这个集合中的用户最喜欢的,且目标用户还未接触过的物品推荐给目标用户
余弦相似度计算公式:
$$
W\mu\nu = \frac {|N(\mu) \bigcap N(\nu)|} {\sqrt{|N(\mu) | N(\nu)}|}
$$
N代表用户喜欢的物品合集。
惩罚了用户u和用户v共同喜欢的热门物品对他们相似度的影响,改进的相似度计算公式:
$$
W\mu\nu = \frac {\sum_{i \in N(\mu) \bigcap N(\nu) } \frac {1} {log(1+|N(i)|)} }{\sqrt{|N(\mu) | N(\nu)}|}
$$
整个算法流程分为两个阶段:
- 训练阶段
- 推荐阶段
对于训练阶段,可分为以下几步:
- 数据预处理,建立User-Item表
- 建立Item-User倒排表
- 建立用户物品交集矩阵
- 建立用户相似度矩阵
对于推荐阶段,可分为以下几步:
- 寻找与被推荐用户最相似的K个用户
- 计算用户对物品的感兴趣列表并逆序排列
ItemCF算法
ItemCF算法的主要步骤如下:
- 计算物品之间的相似度
- 根据物品的相似度和用户的历史行为给用户生成推荐列表
ItemCF算法并不是直接根据物品本身的属性来计算相似度,而是通过分析用户的行为来计算物品之间的相似度。
物品相似度计算公式:
$$
W\mu\nu = \frac {|N(\mu) \bigcap N(\nu)|} {\sqrt{|N(\mu) | N(\nu)}|}
$$
N表示喜欢某物品的用户数量
相似度矩阵归一化处理:Karypis在研究中发现如果将ItemCF的相似度矩阵按最大值归一化,可以提高推荐的准确率。其研究表明,如果已经得到了物品相似度矩阵w,那么可以用如下公式得到归一化之后的相似度矩阵w’:
$$
w_{ij}’ = \frac {w_{ij} } {\max_{j} \ w_{ij} }
$$
实验表明,归一化的好处不仅仅在于增强推荐的准确度,还可以提高推荐的覆盖率和多样性。
整个算法流程分为两个阶段:
- 训练阶段
- 推荐阶段
对于训练阶段,可分为以下几步:
- 数据预处理,建立User-Item表
- 建立物品整体共现矩阵
- 建立物品相似度矩阵
对于推荐阶段,可分为以下几步:
- 寻找与被推荐用户喜爱物品集最相似的N个物品
- 计算用户对这N个物品的感兴趣程序列表并逆序排列
矩阵分解模型(Matrix Factorization)
协同过滤算法处理稀疏矩阵的能力比较弱,为增强泛化能力, 从协同过滤中衍生出矩阵分解模型(MF)或者叫隐语义模型。
(1)MF把用户对item的评分矩阵分解为User矩阵和Item矩阵,其中User矩阵每一行代表一个用户的向量,Item矩阵的每一列代表一个item的向量;
(2)用户i 对item j 的预测评分等于User矩阵的第i 行和Item矩阵的第j 列的内积,预测评分越大表示用户i 喜欢item j 的可能性越大;
(3)MF是把User矩阵和Item矩阵设为未知量,用它们来表示每个用户对每个item的预测评分,然后通过最小化预测评分和实际评分的差异学习出User矩阵和Item矩阵;
(4)MF是一种隐变量模型,它通过在隐类别的维度上去匹配用户和item来做推荐。
(5)MF是一种降维方法,它将用户或item的维度降低到隐类别个数的维度。
Connecting Cluster-specific Models
我们现在有一个模型,可以适应每个领域的特性。在此,我们建议通过使特定领域的参数相互作用来完善这些参数。具体来说,我们对每一层的特定领域参数的交互进行建模通过一个图G其中的节点是该层的所有特定领域参数的集合而eij∈E是连接两个领域节点i和j之间的边,它们可能会相互影响。这解决了我们在上文中提出的缺点,即如果一个领域有很少的分配样本,它的参数将很少被更新,因此在捕捉领域的特殊性和概括同一领域的未见过的样本方面不够稳健。
我们使用GCN来模拟特定领域参数的互动。我们在矩阵V`中收集每个节点的值,即该层的所有特定领域参数。
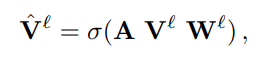
σ为激活函数、A(DxD)是邻接矩阵、W(qxq)是权重投影矩阵,将特定领域参数投影到qxq,在FedCG中我们用该式中计算出的参数替代上面的特定参数,并且 GCN 的权重矩阵也应用 FedAvg 进行参数更新。
没有直接访问服务器端数据的情况下,直接在(特定领域)参数的空间中计算两个领域之间的距离:
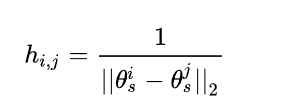
基于此,邻接矩阵定义如下(β代表自连接重要性程度的超参数,通常设置为0.5):
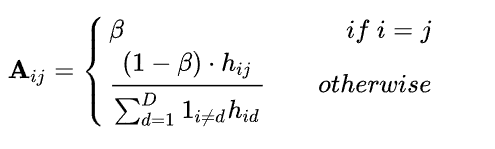
在我们的公式中,每个客户不仅收到了参数集θ,还收到了邻接矩阵。有了这个定义,我们强迫一个特定领域的梯度通过GCN流向所有其他组件。因此,一个特定领域组件的更新将影响所有特定领域的参数,甚至是那些在当前训练中不存在的领域的参数。同时,两组领域特定参数越接近,它们的相互影响就越大。最后,虽然GCN是一种在训练过程中确保跨域信息流动的方法,但在推理时,我们只需预先计算每层的Vˆ,以节省内存的使用。
Experiments
- 本文链接:https://www.xiye7lai.github.io/2023/07/04/recommendation/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。
若您想及时得到回复提醒,建议跳转 GitHub Issues 评论。
若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues