CVPR’21 Cluster-driven Graph Federated Learning over Multiple Domains
论文链接:https://arxiv.org/pdf/2104.14628.pdf
Abstract
联邦学习(FL)涉及到在在隐私受限的情况下学习一个中心模型(即服务器),数据存储在多个设备(即客户端)上,中央模型不能直接访问数据,而只能访问由每个客户在本地计算的参数更新。
这引起了一个问题,被称为统计异构,因为客户可能有不同的数据分布(即领域)。这种情况只能通过对客户进行聚类来一定程度上缓解。聚类可以通过识别域来减少异构性。但它剥夺了每个集群模型的数据和监督。
在这里,我们提出了一种新颖的聚类驱动的图式联合学习(FedCG)。在FedCG中,聚类的作用是解决统计异构,而图卷积网络(GCNs)则可以在它们之间分享知识。
FedCG:
i. 通过符合FL标准的聚类来识别领域,并为每个领域实例化特定的模块;
ii.训练时通过GCN连接特定领域的模块,以学习领域间的相互作用并分享知识;
iii.通过teacher-student分类器训练进行无监督的聚类。并通过他们的领域soft-assignment分数来处理新的未见过的测试领域。
由于GCN对集群的独特的相互作用,FedCG在多个FL基准上达到了最先进的水平。
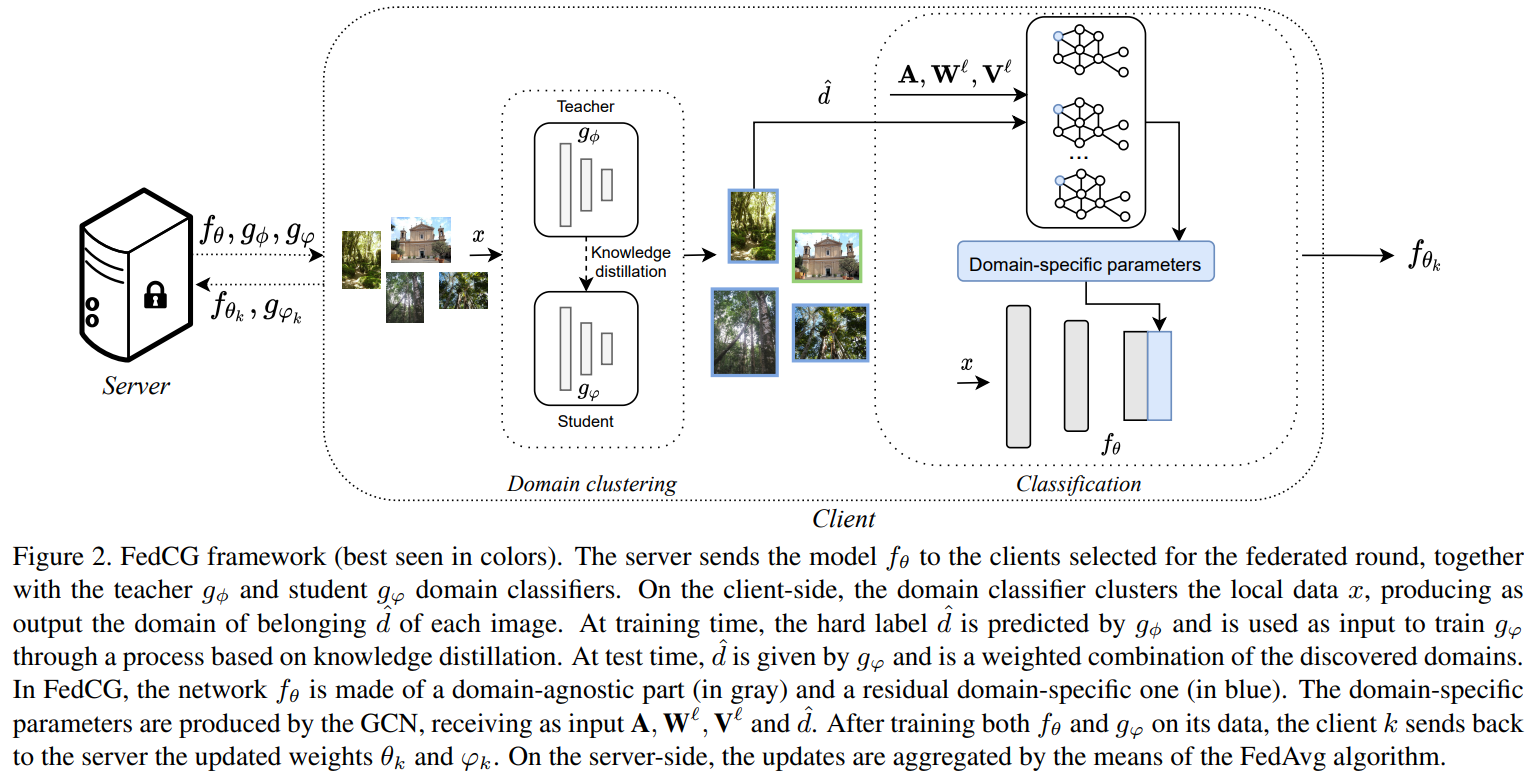
Introduction
FL通常依赖于一个关键的假设,即一个单一的中央模型可以在几个用户之间有效工作。这在实践中可能不成立,因为不同的客户可能持有不同的输入分布,即领域,他们的数据可能不完全分布或不平衡。这些问题意味着分布式优化或集中式训练中的所有IID假设都被违反了。
到目前为止,统计异质性已经被用不同的方法解决了,但没有一种方法对领域间知识的直接共享进行建模:
- convergence analysis and effects (optimize FedAvg)
- meta-learning FL(client-server relation)
- multi-task FL(personal)
- clustering-based FL (split the clients and data, learning separate models)
在这项工作中,我们引入了一个新的集群驱动图联邦学习(FedCG)。FedCG利用了聚类的潜力,同时,FedCG是第一个通过GCN对域与域之间的交互进行建模的方法。
它连接了特定领域的模型组件。在GCN中,每个节点由特定领域的模型参数组成,而邻接矩阵是由特定领域参数之间的反相距离组成。通过这种方式,FedCG不仅可以捕捉到每个领域的特殊性,而且还允许每个领域从其他领域的更新中获益,在训练中分享知识。
我们的聚类是基于无监督的teacher-student分类器训练,它可以推广到未见过的测试领域。我们通过teacher分配、student学习的pseudo-labels进行聚类。这是在FL训练范式中完成的,尊重客户的隐私。这使得我们可以对未见过的新领域的soft-assignments进行估计。
我们的主要贡献是:
1.我们提出了第一个基于集群驱动的GCN方法来解决FL中的统计异质性。由于通过GCN的方式学习了各领域之间的相互作用,知识是基于相似性的标准在各领域之间共享的,减少过度拟合的风险,并帮助人口较少的领域。
2.我们引入了一种为联邦学习场景设计的迭代teacher-student聚类算法,该算法允许通过soft-assignments来适应新的领域。这可以在不违反FL约束的情况下捕捉到多样化的领域分布。每个领域都被分配了特定的模型组件,并通过GCN的相互作用进行训练。
3.我们在多个FL基准上对我们的模型进行了评估,在这些基准上,我们达到了或者说持平最先进的水平。
Cluster-driven Graph Federated Learning
通过聚类识别不同客户端上存在的分布(数据域);
实例化特定于领域的组件以使模型适用于每个领域;
使各个特定于领域的模块通过GCN进行交互,从而使其中一个模块的更新可以使另一个模块受益。
让我们假设我们的数据包含D个域。而D是一个超参数。我们初始化两个领域分类器,即teacher gϕ和student gφ,分别以ϕ和φ为参数。每个领域分类器都是一个函数,将图像映射到概率向量。教师的预测结果作为pseudo-label充当学生分类器预测目标。我们通过迭代最小化教师和学生在Tk上的领域预测之间的交叉熵损失来更新φ:
$$
φ_k=argmin_φ -\frac{1}{n_k}\sum_{(x,y) ∈ T_k}\log g_φ^d(x)
$$
其中d^是由教师分类器基于x给出的pseudo-label,形式化表示为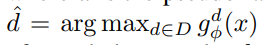
后面表示教师分类器x属于第d个领域的概率。该式鼓励学生能够根据伪标签进行分类,并隐含地鼓励在伪标签上达成一致,从而在聚类上达成一致。并且在 FL 设定下,域分类器的参数在每一个 round 基于标准 FedAvg 进行更新:
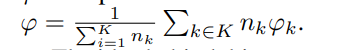
我们的聚类算法可以在测试时将未见过的数据分配到聚类中。
我们可以通过对现有领域的组合来适应属于未见过的领域的数据。此外,在我们的表述中,一个客户的数据样本可能属于多个聚类,考虑到更普遍的情况,即每个客户端可能包含一个以上的数据分布。
Cluster-specific Models
由于我们的模型可以通过前面描述的程序来识别数据集群,我们可以设计一种方法来将函数fθ专门化到每个领域。受多领域学习的启发,我们可以通过特定领域的组件来实现这一点。
我们可以通过特定领域的组件实现这一点。为了简单起见,我们认为参数θ被分成两组,即
θ = {θa, θs} 其中θa(domain-agnostic)是领域无关的参数,θs(domain-specific)是特定领域的参数。请注意,θs实际上是一个集合。
为了使模型适应特定领域的需要,我们可以考虑多种方式,如直接影响可知参数θa或参差激活。这里我们采用后一种策略,因为前者依赖于θa的稳健性,而这在FL中很难保证。
让我们假设fθ是一个深度神经网络,有一组层数L,对于来自某一个领域的输入和由前几层提取得到的特征 z,对于l层输出为:
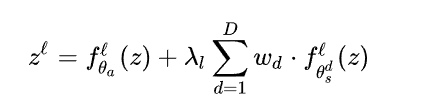
其中λl是一个可学习的参数,以平衡特定领域成分的影响,wd是领域d的权重。在训练过程中,我们假设数据属于一个单一的集群,由教师的伪标签给出。因此,如果d=ˆd,wd为1,否则为0。在测试时,我们希望我们的模型能够处理来自任意领域的数据通过简单地结合所见的残差。因此,我们设定
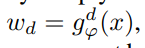
,通过学生域分类器的输出概率来加权每个特定领域组件的影响。在每一轮之后,中央领域的特定参数也必须更新,而不需要访问本地数据。在实践中,我们在每一轮训练中对领域无关的参数和特定领域的参数都进行FedAvg。
Connecting Cluster-specific Models
我们现在有一个模型,可以适应每个领域的特性。在此,我们建议通过使特定领域的参数相互作用来完善这些参数。具体来说,我们对每一层的特定领域参数的交互进行建模通过一个图G其中的节点是该层的所有特定领域参数的集合而eij∈E是连接两个领域节点i和j之间的边,它们可能会相互影响。这解决了我们在上文中提出的缺点,即如果一个领域有很少的分配样本,它的参数将很少被更新,因此在捕捉领域的特殊性和概括同一领域的未见过的样本方面不够稳健。
我们使用GCN来模拟特定领域参数的互动。我们在矩阵V`中收集每个节点的值,即该层的所有特定领域参数。
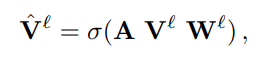
σ为激活函数、A(DxD)是邻接矩阵、W(qxq)是权重投影矩阵,将特定领域参数投影到qxq,在FedCG中我们用该式中计算出的参数替代上面的特定参数,并且 GCN 的权重矩阵也应用 FedAvg 进行参数更新。
没有直接访问服务器端数据的情况下,直接在(特定领域)参数的空间中计算两个领域之间的距离:
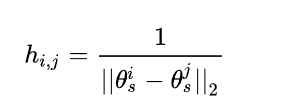
基于此,邻接矩阵定义如下(β代表自连接重要性程度的超参数,通常设置为0.5):
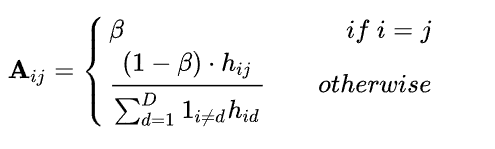
在我们的公式中,每个客户不仅收到了参数集θ,还收到了邻接矩阵。有了这个定义,我们强迫一个特定领域的梯度通过GCN流向所有其他组件。因此,一个特定领域组件的更新将影响所有特定领域的参数,甚至是那些在当前训练中不存在的领域的参数。同时,两组领域特定参数越接近,它们的相互影响就越大。最后,虽然GCN是一种在训练过程中确保跨域信息流动的方法,但在推理时,我们只需预先计算每层的Vˆ,以节省内存的使用。
Experiments
- 本文链接:https://www.xiye7lai.github.io/2022/06/28/CVPR'21%20Cluster-driven%20Graph%20Federated%20Learning%20over%20Multiple%20Domains/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。
若您想及时得到回复提醒,建议跳转 GitHub Issues 评论。
若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues