NeurIPS’21 Federated Graph Classification over Non-IID Graphs (GCFL)
论文链接:https://arxiv.org/pdf/2106.13423.pdf
Abstract
联邦学习已经成为不同领域训练机器学习模型的一个重要方法。
对于比如图分类这种图层面的任务,图也可以被视为一种特殊的数据样本,它可以被收集并存储在不同的独立的本地系统中。与其他领域类似,多个本地系统,每一个都持有一小部分图,可能会合作训练一个强大的图挖掘模型,如流行的图神经网络(GNNs)。
我们分析了来自不同领域的真实世界的图,以确认它们确实共享某些
图的属性,与随机图相比具有统计学意义。然而,我们也发现,不同的图集,即使来自同一领域或
相同的数据集,在图形结构和节点特征方面都是非IID的。为了处理这个问题,我们提出了一个图聚类联合学习(GCFL)框架,该框架基于GNNs的梯度动态地找到本地系统的聚类。
理论上证明这种聚类可以减少本地系统所拥有的图之间的结构和特征的异质性。此外,我们观察到
在GCFL中,GNNs的梯度是相当波动的,这阻碍了高质量的聚类。
我们设计了一种基于梯度序列的动态时间规整(Dynamic Time Warping)聚类机制(GCFL+)。丰富的实验结果和深入的分析证明了我们提出的框架的有效性。
Introduction
随着越来越多的先进技术被开发出来,使用图来模拟和解决现实世界的问题变得越来越流行。
图学习的一个重要场景是图分类,其中的模型如graph kernels和图神经网络被用来预测基于图形特征和结构的图形级标签。
由于FL的关键思想是共享基本的共同信息,现实世界的图保留了许多共同的属性,我们对这个问题感到好奇,即是否来自异质来源(如不同的数据集或甚至不同的领域)的现实世界图能否在彼此之间提供有用的共同信息?为了理解这个问题,我们首先进行初步的数据分析,探索现实世界的图的属性,并试图找到有关在不同数据集的图之间共享的共同模式。
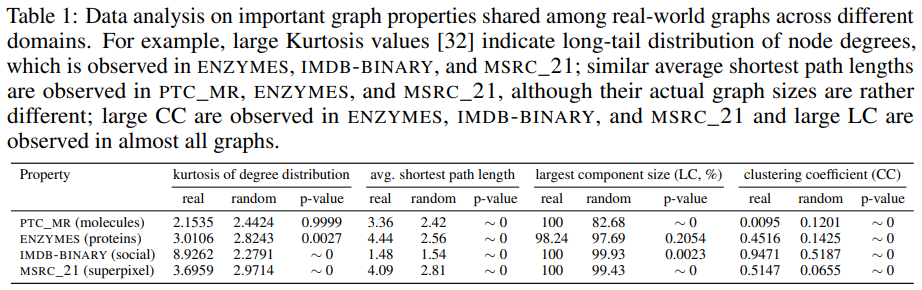
如表1所示,我们分析了四个典型的
数据集,即PTC_MR(分子结构)、ENZYMES(蛋白质结构)、IMDB-BINARY(社交网络)和MSRC_21(超级像素网络)。我们发现它们与具有相同节点和链接数量的随机图相比,确实具有某些统计学上的显著特性。这种观察证实了关于现实世界图的共同模式的说法,这在很大程度上可以影响到图挖掘模型,并促使我们考虑跨数据集甚至是领域的图分类的FL。
虽然图数据集之间存在共同的模式,但我们仍然可以观察到某些异质性。事实上,由于各种原因,详细的图结构分布和节点特征分布都可能出现分歧。
在我们的跨数据集FL设置中,可能具有显著异质性的图为非IID图,这涉及到结构非IID和特征非IID,在这种情况下,像FedAvg这样的天真FL算法可能会失败,甚至适得其反。
此外,由于异质性在不同的案例中是不同的,因此需要一种动态的FL算法来跟踪非IID图的这种异质性,同时进行协作模型训练。
由于观察到一个客户的图可能与某些客户的图相似,但与其他客户的图不相似。将本地客户分配到数据异质性较低的多个聚类中。为此,我们提出了一种新型的图级聚类FL框架(称为GCFL),通过整合强大的图神经诸如GIN等GNNs到聚类FL中,服务器可以根据GNNs的梯度动态地对客户端进行集群,而不需要额外的先验知识,同时在必要时协同训练多个GNN,以实现客户端的同质化聚类。我们从理论上分析了GNN的模型参数确实反映了图的结构和特征,因此,原则上使用GNN的梯度来进行聚类可以得到结构和特征异质性较低的集群。
虽然GCFL在理论上可以实现同质化的集群,但在其训练过程中,我们观察到在每一轮通信中传输的梯度波动很大,这可能是由于客户之间在结构和特征异质性方面的复杂相互作用造成的,使得局部梯度朝着不同的方向发展。在GCFL框架中,服务器会计算一个用于聚类的矩阵,但只根据最后传输的梯度来计算聚类的矩阵,这就忽略了客户端的多轮行为。因此,我们进一步提出了一个改进版的GCFL,它具有基于梯度序列的聚类(称为GCFL+)。
我们在各种设置下进行了广泛的实验,以证明我们的框架的有效性。最后,我们分析了我们的框架的收敛性。实验结果显示,我们新颖的跨数据集/跨特征的设置带来了令人惊讶的积极结果。我们的GCFL+框架可以有效地、持续地超越其他直接的图分类框架,这就是跨数据集/跨领域的FL。
GCFL
Graph Clustered Federated Learning (GCFL)
GCFL的主要思想是寻找具有相似结构的客户集群簇,并在同一簇中的客户中用FedAvg训练图挖掘模型。
GCFL框架通过利用客户端传输的梯度以使更多同质客户之间的合作最大化,并消除异质客户的危害。如果客户的数据分布高度异质性,一般的FL在训练客户时不能共同优化局部损失函数。在这种情况下,经过几轮通信后,一般FL将接近静止点,而且客户传输梯度的范数不会全部趋向于零。因此,在一般FL接近静止点的时候,需要对客户进行聚类。
在这里,我们首先引入一个超参数ε1,作为决定是否停止一般FL的标准,即根据是否接近静止点来决定是否停止一般FL。
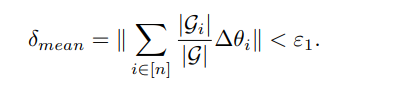
同时,如果有一些客户仍然存在较大的传输梯度范数,这意味着组中的客户是高度异质的,因此需要聚类来消除他们之间的消极影响。然后,我们引入第二个标准,用一个超参数ε2来划分集群。
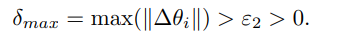
GCFL框架遵循一个自上而下的双分区机制。在每个通信回合t,服务器收到m组梯度来自m个客户端簇。对于一个簇,如果满足以上两个公式,服务器将计算一个簇内的余弦相似度矩阵以建立一个全连接图,节点为簇内的所有客户。Stoer–Wagner minimum分割算法被应用于所构建的图形,该算法对图形进行双分区,并划分出簇Ck→{Ck1, Ck2}。基于以上公式的聚类机制可以自动的、动态的完成簇的划分。
簇类k的客户端i每一个通信轮,将其梯度传输给服务器:
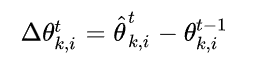
由于服务器维护簇的分配,通过以下方式将梯度按簇进行汇总:
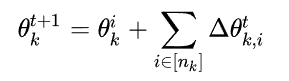
GCFL+:improved GCFL based on observation sequences of gradients
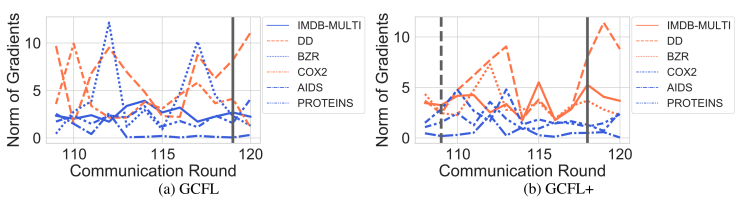
当观察GCFL中每个通信回合的梯度范数时,如图1所示。
我们注意到。1)梯度范数持续波动;2)不同客户的梯度范数有不同的尺度。
梯度范数的波动和不同尺度表明,客户的梯度更新方向和距离是不同的,这体现了结构和特征的异质性。在我们的GCFL框架中,一旦聚类标准得到满足,服务器会根据最后传输的梯度计算余弦相似度矩阵。
然而,根据观察,梯度的规范在通信过程中是波动的。尽管有聚类标准的约束,基于梯度点的GCFL聚类可能会遗漏重要的客户行为,并被噪声所误导。例如,在图1(a)中,GCFL在第119轮基于梯度点进行聚类,在第119轮根据该轮的梯度进行聚类,这并不能有效地找到异质性较低的图。
基于这些观察,我们提出了一个改进的GCFL版本,名为GCFL+,它通过考虑一系列梯度范数来进行聚类。
在GCFL+的框架中,服务器维护一个多变量的时间序列矩阵Q∈R{n,d}其中,n是客户的数量,d是被追踪的梯度序列的长度。在每个通信回合t,服务器更新Q,加入梯度的范数到Q,并删除过时的梯度范数。
GCFL+使用与GCFL相同的聚类标准。如果满足聚类标准,服务器将计算一个距离矩阵β,其中每个元素是两个梯度序列的距离。在这里,我们使用一种叫做动态时间扭曲(DTW)的技术来衡量两个数据序列之间的相似性。
有了这个距离矩阵β,服务器可以对符合聚类标准的簇进行双分区。因此,在图1(b)中。
GCFL+在第118轮基于长度为10的梯度序列进行聚类,这就抓住了客户端的长距离行为,有效地提高了簇的同质性。
Experiments
- 本文链接:https://www.xiye7lai.github.io/2022/06/25/NeurIPS'21%20Federated%20Graph%20Classification%20over%20Non-IID%20Graphs/
- 版权声明:本博客所有文章除特别声明外,均默认采用 许可协议。
若您想及时得到回复提醒,建议跳转 GitHub Issues 评论。
若没有本文 Issue,您可以使用 Comment 模版新建。
GitHub Issues